
Making Peace with LLM Non-determinism
Digging into Sparse MoE and GPU cycles just to realize non-determinism is not new, language is.


Non-determinism in LLMs has always bothered me. I’m often surprised by that one seemingly out-of-nowhere output. This then introduces a series of anxiety about not being able to reliably reproduce user journey, steer the outputs, set up effective unittest/monitoring, or frankly guarantee any product behavior at 100%.
So I took a weekend to understand it. After hours of reading and consulting my chip designer friend Julian, my understanding of the challenge evolved from non-determinism to language itself.
Misconceptions about sampling:
I started from the obvious, sampling. My instinct for sampling was that “The greedier the sampling (Temp=0|top-p=0|top-k=1) the more deterministic it is”. This can be easily demonstrated (e.g. by Marie-Alice’s experiment below where greedier sampling pretty effectively constrains the number of different outputs.)
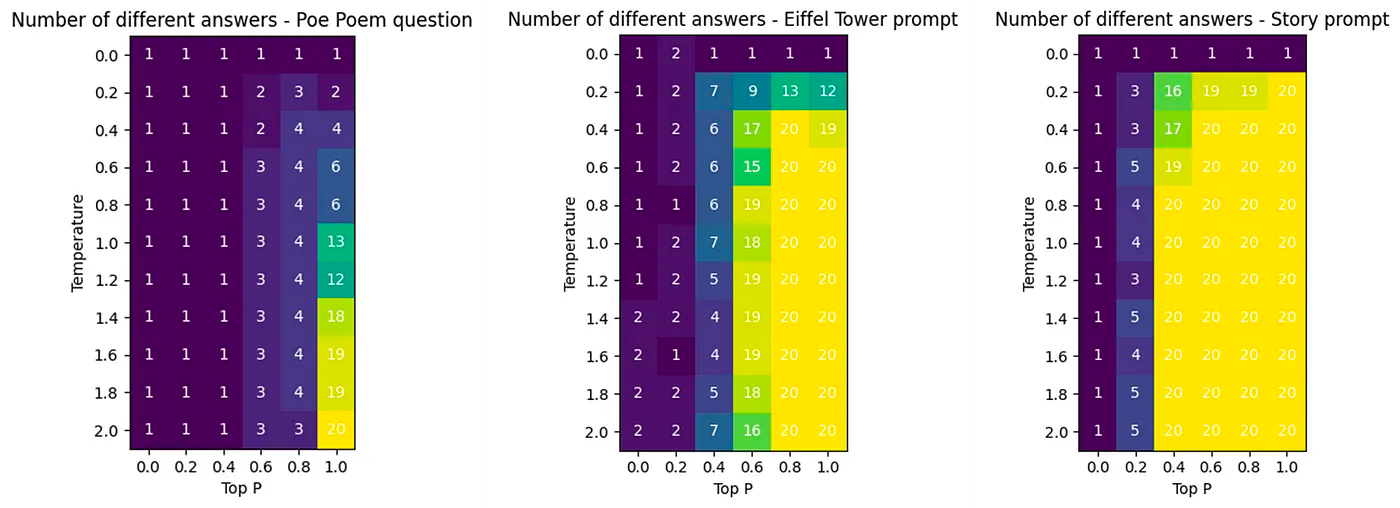
However, while sampling parameters influence the perceived diversity of generated text, sampling itself is a pseudo-random process and we could achieve “same input, same output” with seeding. With proper seeding, the choice of hyperparameters is actually a deterministic optimization problem.
One natural follow-up is “what seed to use”: seed choice introduces variances that matter in some cases (like RL.) One has to decide whether their use cases warrants some understanding or even optimization over, but in most cases, I would just trust whoever set it to 42.
Seeding is all you need, unless you are sparse MoE
Seeding it is then.
Randomness in the sampling process? Seed it: Pytorch, Jax, tensorflow
Have custom operators and code-based components? Seed it: numpy, python
Using the GPT-4 API? Seed it! (cookbook)
Not quite…It's easy to notice that seeded GPT-4 is still not deterministic. One blog post theorized that this is because GPT-4 API likely runs batched inference, and its Mixture of Expert architecture enforces/encourages balance among experts within a batch for efficiency. This means the routing of a sequence depend on its position relative to other sequences in the batch, and determinism only exists for similar batches and not similar inputs. (from Soft MoE paper and Google’s expert choice routing)
This was satisfying enough as batch_size of 1 should still give us determinism if we required it, but there were mentions of hardware non-determinism that I wanted to understand more.
“Hey Julian, what could cause non-determinism at the hardware level?”
Hardware non-determinism
We went down such a deep rabbit hole that Julian might expand on the details in another post, but here’s what I distilled from our chat:
Aside from seed, there are other framework-level controls that guarantee GPU-level determinism (for example, deterministic operation for pytorch and tensorflow.) These controls turned out quite costly:

That “0-10% deceleration” from enabling determinism gave us the clues: Hardware non-determinism often comes from intentional operation implementations that optimize for performance.
Why are performances and determinism at odds? Deterministic outputs across runs often require consistent operation orders because floating point operations aren’t associative. For operation orders to be consistent, synchronization over memory access is required, and it is unfortunately one of the “most expensive operations” for GPUs.

The problem of operation orders gets worse when inference is performed by a network of devices because now we have:
Hardware Variation: frameworks tailor algorithms to each device, so maintaining operation orders across device architectures (e.g. AMD and NVDA) is challenging
Device parallelization: the scale of sharded inference provide more opportunities for non-deterministic behavior to occur per prediction.
These likely explain most of the non-determinism at the hardware level, but there were other sources like the chip’s orientation relative to the sky that we…refuse to comment on.
At the end, we deduced that most ML use cases have prioritized performance over absolute determinism, but this may change if determinism becomes more important. Groq’s marketing of deterministic processor is a prime example.
At this point, most non-determinism from engineering feels well understood and effectively controlled, but something still felt different.
Language
What makes working with LLMs feel random is not just the occasional non-determinism, but language itself.
Language is inherently ambiguous and high-cardinality, and having language as both inputs and outputs makes any perturbation much more nebulous. We generally expect the magnitude of changes in a model's outputs to be proportional to that of its inputs, but language models often break this expectation. A whole paragraph of prompt changes might not steer your stubborn model one bit, but the tiniest differences in punctuation or capitalization could change the entire output. This then propagates to the next token, next LLM, next LLM-system/agent, …
However, this is not without solutions. I summarized some of them that might be helpful here:
Use better models: Lower perplexity and more steerable models will likely partially address the disporportional input-output surprises. Remember using GPT-4 or Claude-2 for the first time?
Reduce unnecessary non-determinism: The output space of LLM is incredibly large, and we should control perturbations that don’t contribute to our goal. Some examples are seeding, greedy sampling, and using more code components.
Reduce ambiguity:
Pre-processing: We could reduce some of the ambiguity outright by consolidating the inputs (e.g. pre-process for typos and synonyms.) This should be immediately effective but likely doesn’t scale well.
Caching: Alternatively, we could cache the outputs and route similar inputs towards them. Some might argue for either low cache hit rate or stiffer responses, but I believe it has its place in exploration cases, like how perplexity’s discover page gracefully turned cached queries into content.
Reduce cardinality:
Guided decoding: GD constrains the sampling to only a subset of tokens, making LLMs more useful for tasks like classification or NER.
Semantic Eval: Semantic metrics (e.g. BERTscore), though limited in precision and often missing nuances, can help group semantically similar sequences and reduce number of distinct entities to consider.
Define clear axes for evaluation: Focusing evals on pre-defined axes (e.g. usefulness/harmfulness) greatly reduces the ambiguous trade-offs of language outputs.
Embrace language and all its random glory
Natively Robust UX: The flexibility of language models give them one of the most robust UXs often with little engineering efforts. It has clear affordances, encourages exploration, and is fairly tolerant to bad inputs.
Exploration: Non-determinism in language models provide us with an effective way to explore. Especially when we ground the results with deterministic scaffold like code-verification (e.g. Alpha Geometry), we can generate and verify ideas on a much wider horizon at very low marginal cost.
That's the end of the journey: Those seemingly random outputs are not always engineering errors to eliminate. They are a chaotic but fascinating property of language models that I might need to be (pleasantly) surprised by from time to time.
 | A guest post by
|
A fascinating read even though parts of this went well above my head. Great title too - it stood out in the sea of HN posts!
Great post! I liked the preprocessing idea - maybe there will be a scientific standard for that at some point