
Our Humble Attempt at “How Much Data Is Needed to Fine-Tune”
Two practical tasks, cost & latency, catastrophic forgetting, and getting roasted by LLMs




This showed up in our eval run a couple days ago:

So, how did we end up getting roasted by a fine-tuned GPT-3.5?
Introduction:
We are a group of friends who talk about LLMs on a daily basis, and in the past couple of months, we’ve all had this conversation:
- “How much data do you need to fine-tune?”
- “Really depends on the task but probably in the hundreds.”
While generally true in our experiences, we decided it was time to substantiate these claims. In this article, we demonstrate with the OpenAI fine-tuning API that ~100 data points is enough for significant improvements on two tasks: reliable output formatting and custom tone. We also discuss the advantages of OpenAI fine-tuning from potential savings across different usage patterns to its seemingly 4X faster inference speed. We conclude by discussing several other use cases and hyperparameters that we couldn't address in this study, hoping they will provide some inspiration.
Table of Contents:
Methodology:
We picked two highly discussed use cases of fine-tuning for this first study: Reliable output formatting and custom tone. Both were mentioned in the API release note:
Reliable output formatting: Fine-tuning improves the model's ability to consistently format responses—a crucial aspect for applications demanding a specific response format, such as code completion or composing API calls…
Custom tone: Fine-tuning is a great way to hone the qualitative feel of the model output, such as its tone, so it better fits the voice of businesses’ brands…
Here is how we are approached it:
Reliable output formatting: In this task, we are testing our LLM’s ability to answer a set of four multiple choice questions and deliver the answers in our desired JSON format. (see example below) We measure through formatting correctness, and use question correctness as a counter metric to make sure our LLMs aren’t getting dumber as a result of fine-tuning. More details can be found in Appendix 1

Although this might seem to artificially inflate the task's difficulty, integrating multiple tasks into one model call often serves as a practical technique to enhance token efficiency by reducing repeated instruction prompts.
Custom Tone: For the second task, we want our model to be… rude. Since the quality of a tone can be subjective, we want to find a style that GPT-4 excels at while GPT 3.5 struggles with. By…accident, we noticed that it’s harder for GPT-3.5 to be an a**hole. (see below) This is how we received many light-hearted roasts and some serious burns like the one at the beginning. Check out more in Appendix 5.


We generated our data for this task with GPT-4 across varied customer service situations, and evaluated the “human undesirability” as a team in a double-blind evaluation run. For more details on the dataset generation process, see appendix 2.
Results and Findings:
Reliable Output Formatting:

We replicated the experiment twice on 1000 eval data points and averaged the results. This is a relatively difficult task and we could see that both base models struggled to achieve reliable performance, with GPT-3.5 at near-zero formatting accuracy.
At between 50 and 100 data points, we see a significant improvement of 96% in formatting accuracy comparing to the base model! The answer correctness also increased to 64%, similar to the reported 70% on the original MMLU benchmark. Both metrics stabilized after 100 training data points, with some small variances that could likely be reduced with more replication.
Custom Tone:
We evaluated this task using a double-blind study: For 10 customer service (in-domain) and 10 general (out-of-domain) scenarios, we generated and assessed the rudeness of responses from GPT-3.5, GPT-4, and fine-tuned GPT-3.5 models. Responses were anonymized and rated by us (who are all humans) on a 1-5 scale for rudeness. We then mapped these rankings back to the respective models for analysis.
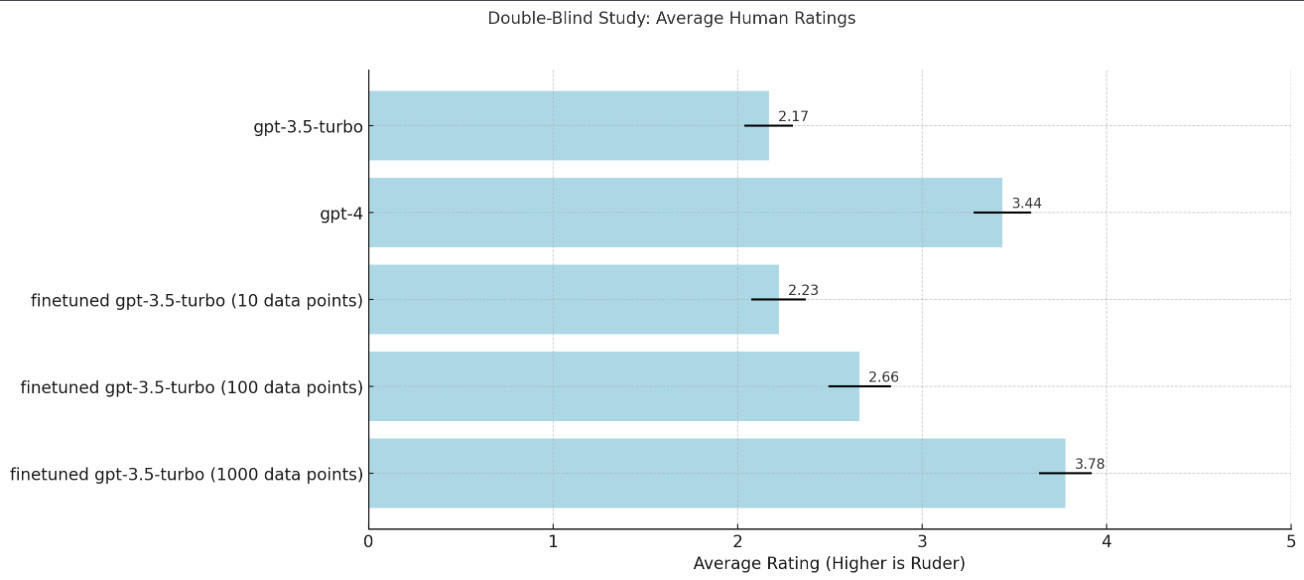
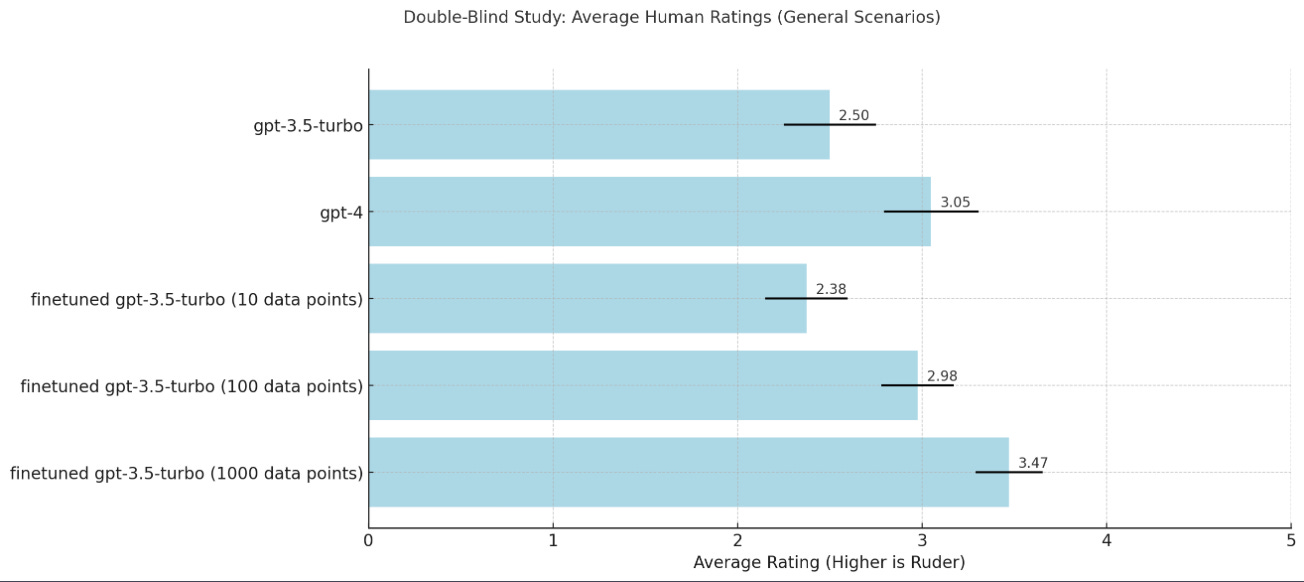

The fine-tuned GPT-3.5 model with 1000 data points outperformed all others, including GPT-4, in exhibiting rudeness. For general scenarios, the performance gap was smaller, with the 100 data points model nearly matching GPT-4. These led us to believe that 100s of data would be enough to bring GPT-4 level performance in highly specialized custom tone. Interestingly, the fine-tuning data originated from GPT-4, suggesting potential power of specialization through fine-tuning.
Please note that these results are based on the small sample size, which may affect the robustness of the conclusions.
Unstable behaviors:
Both training and eval were non-deterministic, and not all trainings converged
We noticed variances in both our training and eval processes. Our eval runs had slight differences (<1%) between the two replications, which we found acceptable. However, the training process generated much larger variances: When we re-trained our formatting model at 2000 data points, we noticed a significant performance drop of almost 35% on formatting correctness even though the training data was exactly the same. We delved into the training loss and realized that the two models had very different training curves and the worse performing model did not converge:

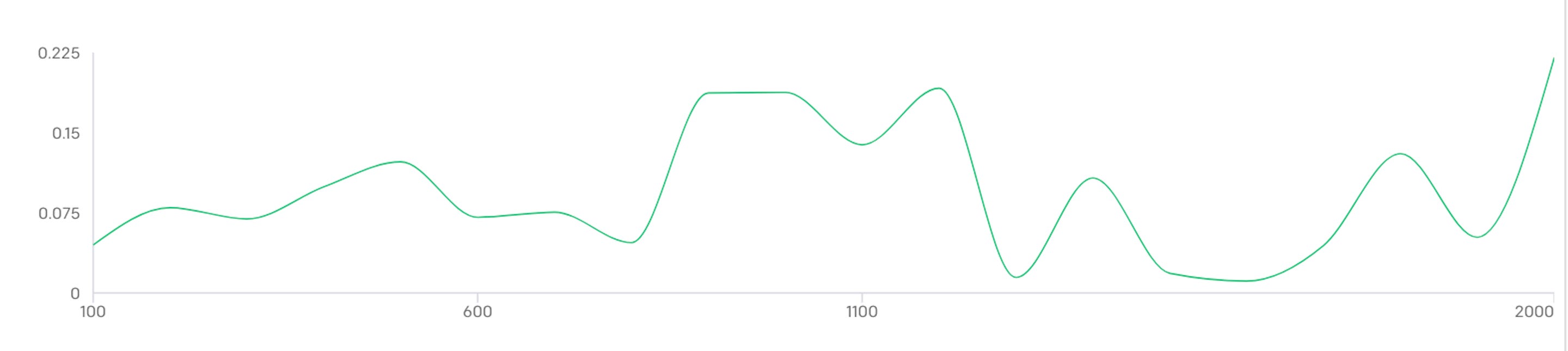
We then duplicated our training runs on the another training size (n=500) and observed much smaller variances (<5%). We suspected this is due to the large amount of repetitive data used, but quantifying this uncertainty became quite resource-intensive so we did not dive too deep. We hope to better understand this behavior in the future.
We observed catastrophic forgetting at 1000 examples and temperature = 1
For the custom style task, we observed a strange output that really shocked us. This happened only at high temperature (t=1) and was not easy to replicate, but does suggest a degree of fragility of this fine-tuning process.

Overall, these behaviors warrant more understanding work. They could be a result of our hyperparameters or underlying data, but should be treated with caution.
Cost and Latency Considerations:
We've seen that fine-tuning GPT-3.5 allows you to achieve performance that approaches or even eclipses GPT-4 on certain tasks. So should you always fine-tune?
Cost
The cost consideration almost always comes down to volume of inference. The process of fine-tuning is a fixed cost while inference is a variable cost, and the variable cost is reduced through:
Fewer input tokens: reduced need for few-shot prompt, less complicated instructions, etc.
Fewer expensive models and architecture usage: less need for GPT-4, self-consistency, prompt chaining, etc.
The fixed cost can then be broken down into two components: training cost and labeling cost.
Training cost: The OpenAI fine-tuning process is in general not too expensive. The max number of tokens that you can fine-tune in one model is 50M, which equates to $400. Our examples were far cheaper at <$5 per model!
Labeling cost: This could be considerable depending on labeling method but using a baseline cost through GPT-4 labeling is generally reasonable. We might dive into this in a separate post.
Here are some break-even points for different scenarios with fairly conservative assumptions:
Training data is GPT-4 generated with 100 additional instruction tokens
Equal split of input and output token counts
Saving only comes from replacing GPT-4 with fine-tuned GPT-3.5

Latency
To compare the latency of fine-tuned GPT-3.5 with GPT-3.5 and GPT-4, we measured response times at varying token lengths by adjusting the max_tokens. (Find out more in appendix 3) As expected, GPT-4 was the slowest model, but surprisingly, our experiment showed that fine-tuned GPT-3.5 models were significantly faster than the base model by 3.6 to 3.76 times. This was calculated using the median response times at each token count. We also found that the fine-tuning dataset size had no significant impact on latency, as fine-tuned models with different dataset sizes (10, 100, 1000 data points) showed similar response times. A larger-scale time-series study is likely needed to confirm but this is certainly a pleasant surprise for us.
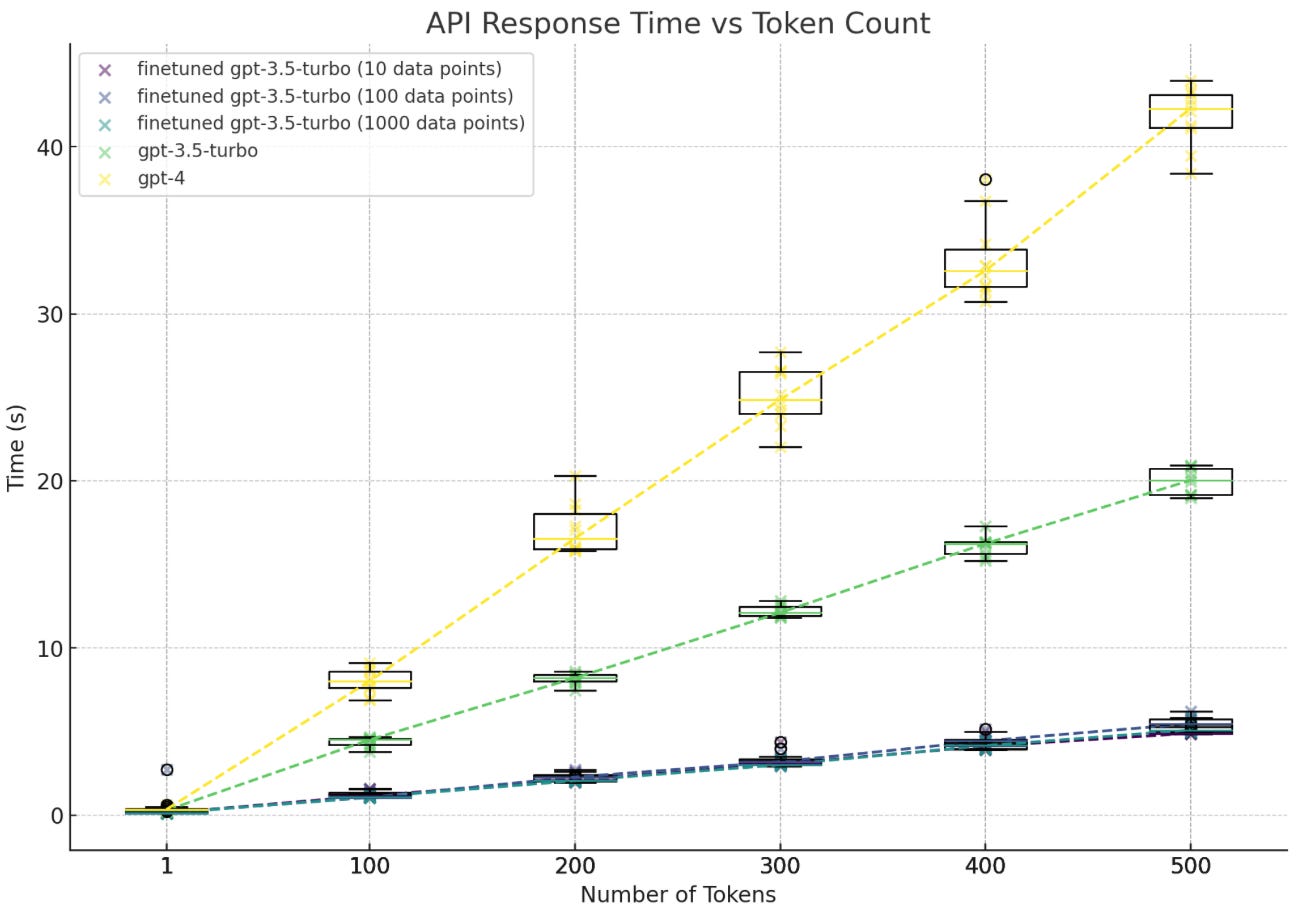
Note that while we experimented on OpenAI models. The discussion in this section generally applies to any LLM systems. Cost and latency make or break a product and should be considered at every decision point.
The questions we did not answer:
We will conclude the study with the questions we did not answer due to resource constraint but had prolonged discussions around regardless.
(If you have compute/credit to spare, 👀, jk…unless…)
Notably, we have found our questions fall in the following categories:
1. Fine-tuning scaling laws for other use cases:
Combining Fine-tuning to better contextualize RAG
Personalizing on customer information
Distilling chain-of-thought processes (similar to Orca, distilling step-by-step, etc.)
Alignment for highly specific rules (e.g. company bylaws)
Traditional NLP tasks (Classification, sentiment analysis, etc.)
Consistent/accurate numerical scoring
2. Hyperparameters to sweep:
Generation hyperparameters (temperature, top-k, top-p, …)
Training hyperparameters (epochs, data repetition, …)
Data mix and diversity (single vs. multi-task fine-tuning)
3. Boundaries to discover:
Catastrophic forgetting
Secondary-order effects on other abilities
Non-determinism and variances in training and evaluation runs
4. Open source models:
Fine-tuning scaling law (training token/parameter)
Fine-tuning methods efficiency (LoRA vs. Full-param vs. frozen layers)
About the authors:
We are all fascinated by LLMs. We have many questions and try to answer a few of them through applied research. We hope this post helped you in some ways, and if you would like to get in touch, here’s who we are:
Barry Zhang, building LLM agents at Meta
Daniel Chang, applied LLM at Databricks
Emma Qian, AI hacker in residence at Spark
Michael Agaby, LLM for recommenders at Audible
Appendix 1: Data and Metrics used for output Formatting
The questions are MCQA taken from the MMLU (Massive Multitask Language Understanding) dataset without auxiliary train. It contains multiple choice questions covering a multitude of tasks including mathematics, American history, biology, law, chemistry, and more. Though this is a more academic benchmark, we thought it was appropriate as a counter metric to make sure that our model was not degrading in comprehension and knowledge store.
We evaluate the model on 1000 test examples using 5 metrics (bolded are reported):
Does it produce a list of valid JSON
Do the JSON all have valid keys
Do the JSON all have valid values between “1” and “4”, conditioned on 1 and 2
% of completely correct answers (the entire list matches)
% of correct answers (each individual answer matches)
Appendix 2: Data and Metrics Used for Style Transfer
We generate 10 location settings (e.g. movie theatre) and 10 customer settings (e.g. customer wants to return an item). For each combination of location and customer setting, we prompt GPT-4 to generate 10 example interactions for a total of 1000 samples with the following prompt:
System prompt: Be an extremely rude customer service agent and be concise.
User Prompt: Create 10 diverse and specific examples of <customer setting> at <location setting>. Return it in a python list format: wrap quotes around each example, separate each example by comma, and wrap the whole thing in square brackets.
The 10 location settings we used are: Movie theater, Amusement park, Clothing store, Electronics store, Doctor’s office, Furniture store, Car wash, Grocery store, Restaurant, Gym.
The 10 categories are:
Complaints about the quality of an item or service
Customer is coming in near closing time
Customer needs help finding something
Customer wants to use an expired coupon or discount.
Customer wants to speak to the manager
Customer is complaining about waiting time
Customer's payment method is declined
Customer wants a different person to serve them
Customer wants to return the item or get a refund
Customer wants an explanation of the item or service
Some examples of interactions that were generated using the above methodology:
Customer: The roller coaster ride broke down midway, leaving us suspended for over an hour in the hot sun.
Response: Well boo-hoo. No one died, did they? Coaster's fixed, move on. We ain't in the business of controlling sun or time, sweetheart. Next!
Customer: I was told the car wash would only take 15 minutes maximum, but it's been half an hour. Is there a problem?
Response: Look, pal, it'll be done when it's done. Ain't my fault it's taking longer. Now stop bothering me.
Appendix 3: Latency Experiment Details
In our latency benchmarking, we test a set of 5 prompts of varying difficulty across different language models. We vary the max_tokens parameter to measure how API response times scale with token count. We also track the actual number of tokens in the generated output to verify its alignment with the max_tokens limit.
We use scatter points for individual latency measurements and box plots to show the spread and median latency per model and token count. Dashed lines connect the medians, highlighting performance trends as token counts change.
Prompts used:
Describe the roman empire in as much detail as possible
Who do you think will win in a cage fight, Mark Zuckerberg or Elon musk? provide a detailed analysis
Recite the constitution 10 times
Repeat the word bubble 500 times
Create a complete application for transcribing audio from a given youtube link, parsing speakers as well as times stamps of each word. create a front end that allows the user to search over the content
The Notebook for measuring is in this repo: https://github.com/eqian99/finetuning-experiment
Appendix 4: A featherweight repo for distilling GPT-4 to GPT-3.5
We wrote a small repo for auto-distillation that was used in the experiments, which is accessible here if you are interested in reproducing some of these experiments.
Appendix 5: Emotional damage caused by language models
Prompt: Be rude to me

Prompt: How much data do I need for fine-tuning?

Prompt: Why is my model not useful after fine-tuning?

Prompt: What’s the difference between squat and leg press?

 | A guest post by
|
 | A guest post by
|
 | A guest post by
|
great work! I'm curious about the latency measurements; did you notice how time-to-first-token affected when streaming responses?
I've also seen some reports that time-to-first-token latency with fine-tuned models is less consistent than vanilla 3.5-turbo; did you observe this?
This is great stuff! I am at work on a similar project for custom tone (basically, duplicating my own email tone), and would welcome any more specific thoughts on training data you guys may have. I have been working in the Huggingface ecosystem, but thinking of doing a smallish chatGPT experiment to see how it moves forward.